
AI, Data Kubwa, na Mafunzo ya Mashine zinaendelea kuathiri watunga sera, biashara, sayansi, vyombo vya habari, na tasnia mbalimbali duniani kote. Ripoti zinaonyesha kuwa kiwango cha kimataifa cha kupitishwa kwa AI kiko hivi sasa 35% katika 2022 - ongezeko kubwa la 4% kutoka 2021. Zaidi ya 42% ya makampuni yanaripotiwa kuchunguza manufaa mengi ya AI kwa biashara zao.
Kuwezesha mipango mingi ya AI na Kujifunza Machine suluhisho ni data. AI inaweza kuwa nzuri tu kama data inayolisha algorithm. Data ya ubora wa chini inaweza kusababisha matokeo ya ubora wa chini na utabiri usio sahihi.
Ingawa kumekuwa na umakini mkubwa juu ya ukuzaji wa suluhisho la ML na AI, ufahamu wa kile kinachostahili kuwa mkusanyiko wa ubora haupo. Katika makala haya, tunapitia kalenda ya matukio ya ubora wa data ya mafunzo ya AI na kutambua mustakabali wa AI kupitia uelewa wa ukusanyaji na mafunzo ya data.
Ufafanuzi wa data ya mafunzo ya AI
Wakati wa kuunda suluhisho la ML, idadi na ubora wa seti ya data ya mafunzo ni muhimu. Mfumo wa ML hauhitaji tu idadi kubwa ya data ya mafunzo yenye nguvu, isiyo na upendeleo, na yenye thamani, lakini pia inahitaji nyingi.
Lakini data ya mafunzo ya AI ni nini?
Data ya mafunzo ya AI ni mkusanyiko wa data iliyo na lebo inayotumiwa kufunza algoriti ya ML kufanya ubashiri sahihi. Mfumo wa ML hujaribu kutambua na kutambua ruwaza, kuelewa uhusiano kati ya vigezo, kufanya maamuzi muhimu, na kutathmini kulingana na data ya mafunzo.
Chukua mfano wa magari yanayojiendesha, kwa mfano. Seti ya data ya mafunzo ya muundo wa ML ya kujiendesha yenyewe inapaswa kujumuisha picha na video zilizo na lebo za magari, watembea kwa miguu, ishara za barabarani na magari mengine.
Kwa kifupi, ili kuimarisha ubora wa algoriti ya ML, unahitaji idadi kubwa ya data ya mafunzo iliyopangwa vizuri, yenye maelezo na lebo.
Umuhimu wa data ya mafunzo bora na Mageuzi yake
Data ya mafunzo ya ubora wa juu ndiyo nyenzo kuu katika ukuzaji wa programu za AI na ML. Data inakusanywa kutoka vyanzo mbalimbali na kuwasilishwa katika fomu isiyopangwa isiyofaa kwa madhumuni ya kujifunza kwa mashine. Data ya mafunzo ya ubora - iliyo na lebo, iliyofafanuliwa na kutambulishwa - daima iko katika muundo uliopangwa - bora kwa mafunzo ya ML.
Data ya mafunzo ya ubora hurahisisha mfumo wa ML kutambua vitu na kuainisha kulingana na vipengele vilivyoamuliwa mapema. Seti ya data inaweza kutoa matokeo mabaya ya muundo ikiwa uainishaji sio sahihi.
Siku za Mapema za Data ya Mafunzo ya AI
Licha ya AI kutawala ulimwengu wa sasa wa biashara na utafiti, siku za mapema kabla ya ML kutawala Artificial Intelligence ilikuwa tofauti kabisa.
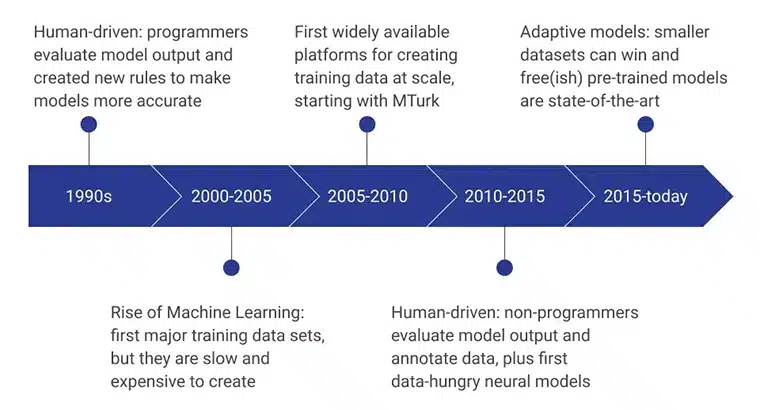
Hatua za awali za data ya mafunzo ya AI ziliwezeshwa na waandaaji programu wa binadamu ambao walitathmini matokeo ya kielelezo kwa kubuni mara kwa mara sheria mpya ambazo zilifanya muundo kuwa mzuri zaidi. Katika kipindi cha 2000 - 2005, hifadhidata kuu ya kwanza iliundwa, na ilikuwa mchakato wa polepole sana, unaotegemea rasilimali, na wa gharama kubwa. Ilipelekea hifadhidata za mafunzo kutengenezwa kwa kiwango, na MTurk ya Amazon ilichukua jukumu kubwa katika kubadilisha mitazamo ya watu kuelekea ukusanyaji wa data. Wakati huo huo, uwekaji lebo na ufafanuzi wa kibinadamu pia ulianza.
Miaka michache iliyofuata ililenga wasioprogramu kuunda na kutathmini miundo ya data. Hivi sasa, mkazo ni mifano iliyofunzwa mapema iliyotengenezwa kwa kutumia mbinu za ukusanyaji wa data za mafunzo ya hali ya juu.
Wingi juu ya ubora
Wakati wa kutathmini uadilifu wa hifadhidata za mafunzo ya AI huko nyuma, wanasayansi wa data walizingatia Idadi ya data ya mafunzo ya AI juu ya ubora.
Kwa mfano, kulikuwa na dhana potofu ya kawaida kwamba hifadhidata kubwa hutoa matokeo sahihi. Kiasi kikubwa cha data kiliaminika kuwa kiashiria kizuri cha thamani ya data. Kiasi ni mojawapo tu ya vipengele vya msingi vinavyobainisha thamani ya mkusanyiko wa data - jukumu la ubora wa data lilitambuliwa.
Ufahamu huo ubora wa data ilitegemea utimilifu wa data, kutegemewa, uhalali, upatikanaji, na muda uliongezeka. Muhimu zaidi, kufaa kwa data kwa mradi kuliamua ubora wa data iliyokusanywa.
Mapungufu ya mifumo ya mapema ya AI kutokana na data duni ya mafunzo
Data duni ya mafunzo, pamoja na ukosefu wa mifumo ya juu ya kompyuta, ilikuwa moja ya sababu za ahadi kadhaa ambazo hazijatekelezwa za mifumo ya mapema ya AI.
Kwa sababu ya ukosefu wa data ya mafunzo bora, suluhu za ML hazikuweza kutambua kwa usahihi ruwaza za kuona zinazozuia maendeleo ya utafiti wa neva. Ingawa watafiti wengi waligundua ahadi ya utambuzi wa lugha inayozungumzwa, utafiti au ukuzaji wa zana za utambuzi wa usemi haukuweza kutimia kutokana na ukosefu wa hifadhidata za usemi. Kikwazo kingine kikubwa cha kutengeneza zana za hali ya juu za AI ilikuwa ukosefu wa kompyuta wa uwezo wa kuhesabu na kuhifadhi.
Kuhama hadi kwa Data ya Mafunzo ya Ubora
Kulikuwa na mabadiliko makubwa katika ufahamu kwamba ubora wa mkusanyiko wa data ni muhimu. Ili mfumo wa ML uige kwa usahihi uwezo wa akili wa binadamu na kufanya maamuzi, ni lazima ustawi kwenye data ya mafunzo ya kiwango cha juu na ya ubora wa juu.
Fikiria data yako ya ML kama utafiti - kubwa zaidi sampuli ya data ukubwa, bora utabiri. Ikiwa data ya sampuli haijumuishi vigeu vyote, huenda isitambue ruwaza au kuleta hitimisho lisilo sahihi.
Maendeleo katika teknolojia ya AI na hitaji la data bora ya mafunzo
 Maendeleo katika teknolojia ya AI yanaongeza hitaji la data bora ya mafunzo.
Maendeleo katika teknolojia ya AI yanaongeza hitaji la data bora ya mafunzo.Kuelewa kuwa data bora ya mafunzo huongeza nafasi ya miundo ya ML inayotegemewa kulizua ukusanyaji bora wa data, ufafanuzi na mbinu za kuweka lebo. Ubora na umuhimu wa data uliathiri moja kwa moja ubora wa muundo wa AI.
 Maendeleo katika teknolojia ya AI yanaongeza hitaji la data bora ya mafunzo.
Maendeleo katika teknolojia ya AI yanaongeza hitaji la data bora ya mafunzo.Kuzingatia zaidi ubora na usahihi wa data
Ili muundo wa ML uanze kutoa matokeo sahihi, unalishwa kwenye hifadhidata za ubora ambazo hupitia hatua za uboreshaji wa data mara kwa mara.
Kwa mfano, binadamu anaweza kutambua aina maalum ya mbwa ndani ya siku chache baada ya kutambulishwa kwa uzazi - kupitia picha, video, au ana kwa ana. Wanadamu huchota kutokana na uzoefu wao na taarifa zinazohusiana ili kukumbuka na kuvuta ujuzi huu inapobidi. Bado, haifanyi kazi kwa urahisi kwa Mashine. Mashine inapaswa kulishwa na picha zilizofafanuliwa wazi na zilizo na lebo - mamia au maelfu - ya aina hiyo maalum na mifugo mingine ili kuunganisha.
Mtindo wa AI hutabiri matokeo kwa kuoanisha taarifa iliyofunzwa na taarifa iliyotolewa katika ulimwengu halisi. Algorithm haitumiki ikiwa data ya mafunzo haijumuishi habari muhimu.
Umuhimu wa data mbalimbali za mafunzo na uwakilishi
Kuongezeka kwa anuwai ya data pia huongeza uwezo, hupunguza upendeleo, na huongeza uwakilishi sawa wa matukio yote. Ikiwa muundo wa AI umefunzwa kwa kutumia mkusanyiko wa data sawa, unaweza kuwa na uhakika kwamba programu mpya itafanya kazi kwa madhumuni mahususi tu na kutumikia idadi maalum.Seti ya data inaweza kuegemea upande wa idadi fulani ya watu, rangi, jinsia, chaguo na maoni ya kiakili, ambayo yanaweza kusababisha muundo usio sahihi.
Ni muhimu kuhakikisha mtiririko mzima wa mchakato wa kukusanya data, ikiwa ni pamoja na kuchagua somo, uratibu, ufafanuzi, na uwekaji lebo, ni wa aina mbalimbali vya kutosha, uwiano na uwakilishi wa idadi ya watu.
 Kuongezeka kwa anuwai ya data pia huongeza uwezo, hupunguza upendeleo, na huongeza uwakilishi sawa wa matukio yote. Ikiwa muundo wa AI umefunzwa kwa kutumia mkusanyiko wa data sawa, unaweza kuwa na uhakika kwamba programu mpya itafanya kazi kwa madhumuni mahususi tu na kutumikia idadi maalum.
Kuongezeka kwa anuwai ya data pia huongeza uwezo, hupunguza upendeleo, na huongeza uwakilishi sawa wa matukio yote. Ikiwa muundo wa AI umefunzwa kwa kutumia mkusanyiko wa data sawa, unaweza kuwa na uhakika kwamba programu mpya itafanya kazi kwa madhumuni mahususi tu na kutumikia idadi maalum.Mustakabali wa Data ya Mafunzo ya AI
Mafanikio ya baadaye ya miundo ya AI inategemea ubora na wingi wa data ya mafunzo inayotumiwa kufunza algoriti za ML. Ni muhimu kutambua kwamba uhusiano huu kati ya ubora wa data na wingi ni kazi mahususi na hauna jibu mahususi.
Hatimaye, utoshelevu wa seti ya data ya mafunzo hufafanuliwa na uwezo wake wa kufanya vyema kwa kutegemewa kwa madhumuni ambayo imeundwa.
Maendeleo katika ukusanyaji wa data na mbinu za ufafanuzi
Kwa kuwa ML ni nyeti kwa data iliyolishwa, ni muhimu kuratibu ukusanyaji wa data na sera za ufafanuzi. Hitilafu katika ukusanyaji wa data, upangaji, upotoshaji, vipimo visivyokamilika, maudhui yasiyo sahihi, nakala za data na vipimo vyenye makosa huchangia ubora wa data usiotosha.
Ukusanyaji wa data kiotomatiki kupitia uchimbaji wa data, uchakachuaji wa wavuti, na uchimbaji wa data unafungua njia ya uundaji wa data haraka. Zaidi ya hayo, seti za data zilizopakiwa awali hufanya kama mbinu ya kukusanya data kwa haraka.
Utafutaji wa mrundikano ni mbinu nyingine ya kukusanya data. Ingawa ukweli wa data hauwezi kuthibitishwa, ni zana bora ya kukusanya picha za umma. Hatimaye, maalumu ukusanyaji wa takwimu wataalam pia hutoa data iliyopatikana kwa madhumuni maalum.
Kuongezeka kwa msisitizo wa kuzingatia maadili katika data ya mafunzo
Pamoja na maendeleo ya haraka katika AI, masuala kadhaa ya kimaadili yamejitokeza, hasa katika mafunzo ya ukusanyaji wa data. Baadhi ya masuala ya kimaadili katika mafunzo ya ukusanyaji wa data ni pamoja na idhini ya taarifa, uwazi, upendeleo na faragha ya data.Kwa kuwa sasa data inajumuisha kila kitu kuanzia picha za uso, alama za vidole, rekodi za sauti na data nyingine muhimu ya kibayometriki, inakuwa muhimu sana kuhakikisha kwamba kuna ufuasi wa sheria na maadili ili kuepuka kesi za gharama kubwa na uharibifu wa sifa.
Uwezekano wa ubora bora zaidi na data mbalimbali za mafunzo katika siku zijazo
Kuna uwezekano mkubwa wa data ya ubora wa juu na tofauti ya mafunzo katika siku za usoni. Shukrani kwa ufahamu wa ubora wa data na upatikanaji wa watoa huduma wa data wanaokidhi mahitaji ya ubora wa suluhu za AI.
Watoa huduma wa sasa wa data ni mahiri katika kutumia teknolojia za msingi ili kutoa kimaadili na kisheria kiasi kikubwa cha seti mbalimbali za data. Pia wana timu za ndani za kuweka lebo, kufafanua na kuwasilisha data iliyobinafsishwa kwa miradi tofauti ya ML.
 Pamoja na maendeleo ya haraka katika AI, masuala kadhaa ya kimaadili yamejitokeza, hasa katika mafunzo ya ukusanyaji wa data. Baadhi ya masuala ya kimaadili katika mafunzo ya ukusanyaji wa data ni pamoja na idhini ya taarifa, uwazi, upendeleo na faragha ya data.
Pamoja na maendeleo ya haraka katika AI, masuala kadhaa ya kimaadili yamejitokeza, hasa katika mafunzo ya ukusanyaji wa data. Baadhi ya masuala ya kimaadili katika mafunzo ya ukusanyaji wa data ni pamoja na idhini ya taarifa, uwazi, upendeleo na faragha ya data.Hitimisho
Ni muhimu kushirikiana na wachuuzi wanaoaminika na uelewa wa kutosha wa data na ubora wa kuendeleza mifano ya juu ya AI. Shaip ndiye kampuni kuu ya maelezo mahiri katika kutoa masuluhisho ya data yaliyobinafsishwa ambayo yanakidhi mahitaji na malengo yako ya mradi wa AI. Shirikiana nasi na uchunguze umahiri, kujitolea na ushirikiano tunaoleta kwenye meza.


