

Miundo Kubwa ya Lugha ni Gani?
Miundo Kubwa ya Lugha (LLMs) ni mifumo ya hali ya juu ya akili ya bandia (AI) iliyoundwa ili kuchakata, kuelewa na kutoa maandishi yanayofanana na binadamu. Zinatokana na mbinu za kujifunza kwa kina na zimefunzwa kwenye seti kubwa za data, kwa kawaida huwa na mabilioni ya maneno kutoka vyanzo mbalimbali kama vile tovuti, vitabu na makala. Mafunzo haya ya kina huwezesha LLMs kufahamu nuances ya lugha, sarufi, muktadha, na hata baadhi ya vipengele vya ujuzi wa jumla.
Baadhi ya LLM maarufu, kama vile GPT-3 ya OpenAI, huajiri aina ya mtandao wa neva unaoitwa kibadilishaji, ambacho huziruhusu kushughulikia kazi changamano za lugha kwa ustadi wa ajabu. Mifano hizi zinaweza kufanya kazi mbalimbali, kama vile:
- Kujibu maswali
- Kufupisha maandishi
- Tafsiri ya lugha
- Kuzalisha maudhui
- Hata kushiriki katika mazungumzo maingiliano na watumiaji
Kadiri LLM zinavyoendelea kubadilika, zina uwezo mkubwa wa kuimarisha na kuweka kiotomatiki matumizi mbalimbali katika tasnia, kutoka huduma kwa wateja na uundaji wa maudhui hadi elimu na utafiti. Hata hivyo, pia yanaibua wasiwasi wa kimaadili na kijamii, kama vile tabia ya upendeleo au matumizi mabaya, ambayo yanahitaji kushughulikiwa kadri teknolojia inavyoendelea.

Mifano Maarufu ya Miundo Kubwa ya Lugha
Hapa kuna mifano michache maarufu ya LLM zinazotumiwa sana katika wima tofauti za tasnia:
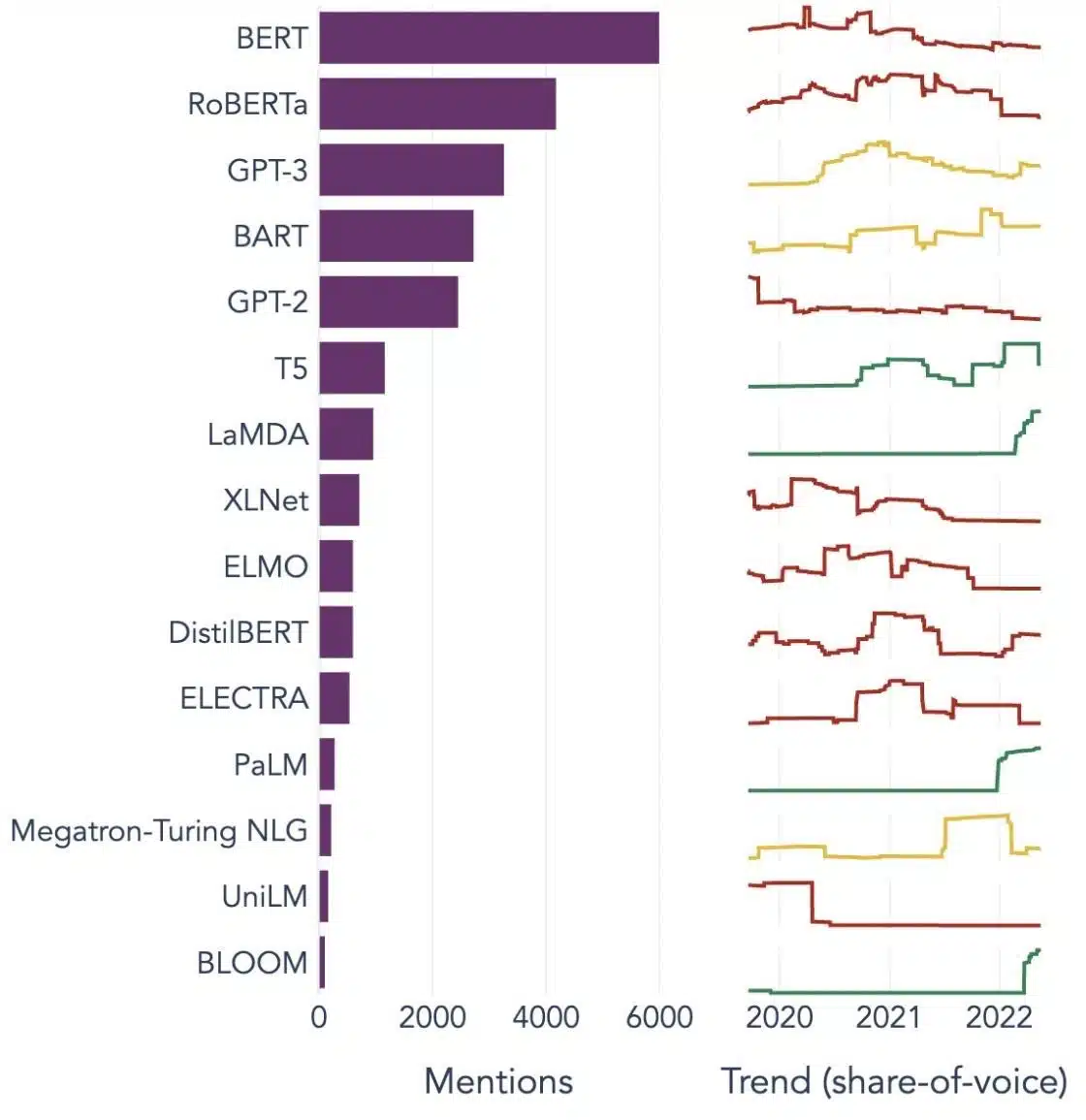
Chanzo cha picha: Kuelekea Sayansi ya data
Vielelezo vya LLM vinafunzwa vipi?
Kufundisha miundo mikubwa ya lugha (LLMs) ni kazi nzuri ambayo inahusisha hatua kadhaa muhimu. Hapa kuna muhtasari wa hatua kwa hatua uliorahisishwa:
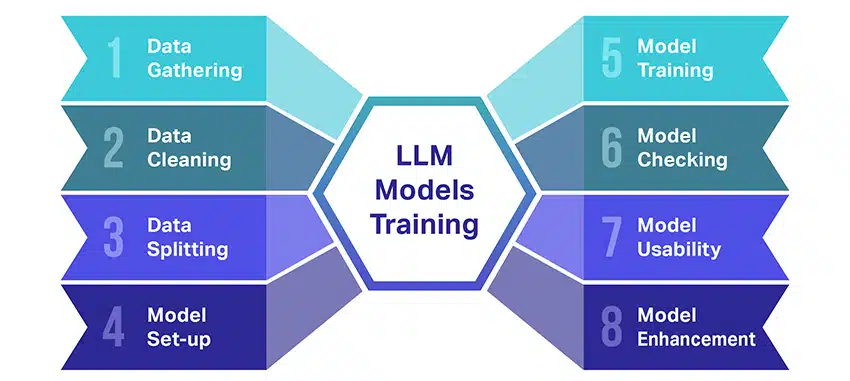
- Kukusanya Data ya Maandishi: Mafunzo ya LLM huanza na mkusanyiko wa idadi kubwa ya data ya maandishi. Data hii inaweza kutoka kwa vitabu, tovuti, makala, au majukwaa ya mitandao ya kijamii. Lengo ni kunasa utanzu mwingi wa lugha ya binadamu.
- Kusafisha Data: Data ya maandishi ghafi kisha hupangwa katika mchakato unaoitwa preprocessing. Hii inajumuisha kazi kama vile kuondoa herufi zisizohitajika, kugawanya maandishi katika sehemu ndogo zinazoitwa tokeni, na kuyaweka yote katika muundo ambao muundo unaweza kufanya kazi nao.
- Kugawanya Data: Ifuatayo, data safi imegawanywa katika seti mbili. Seti moja, data ya mafunzo, itatumika kufunza modeli. Seti nyingine, data ya uthibitishaji, itatumika baadaye kupima utendakazi wa modeli.
- Kuweka Mfano: Muundo wa LLM, unaojulikana kama usanifu, basi hufafanuliwa. Hii inahusisha kuchagua aina ya mtandao wa neva na kuamua juu ya vigezo mbalimbali, kama vile idadi ya safu na vitengo vilivyofichwa ndani ya mtandao.
- Kufundisha Mfano: Mafunzo halisi yanaanza sasa. Mfano wa LLM hujifunza kwa kuangalia data ya mafunzo, kufanya utabiri kulingana na kile ambacho umejifunza hadi sasa, na kisha kurekebisha vigezo vyake vya ndani ili kupunguza tofauti kati ya utabiri wake na data halisi.
- Kukagua Mfano: Ujifunzaji wa modeli ya LLM huangaliwa kwa kutumia data ya uthibitishaji. Hii husaidia kuona jinsi muundo unavyofanya kazi vizuri na kurekebisha mipangilio ya muundo kwa utendakazi bora.
- Kutumia Mfano: Baada ya mafunzo na tathmini, modeli ya LLM iko tayari kutumika. Sasa inaweza kuunganishwa katika programu au mifumo ambapo itatoa maandishi kulingana na ingizo mpya zilizotolewa.
- Uboreshaji wa Mfano: Hatimaye, daima kuna nafasi ya kuboresha. Muundo wa LLM unaweza kuboreshwa zaidi baada ya muda, kwa kutumia data iliyosasishwa au kurekebisha mipangilio kulingana na maoni na matumizi ya ulimwengu halisi.
Kumbuka, mchakato huu unahitaji rasilimali muhimu za hesabu, kama vile vitengo vya usindikaji vyenye nguvu na hifadhi kubwa, pamoja na ujuzi maalum katika kujifunza kwa mashine. Ndio maana kwa kawaida hufanywa na mashirika au kampuni za utafiti zilizojitolea zilizo na ufikiaji wa miundombinu muhimu na utaalam.
Je, LLM Inategemea Mafunzo Yanayosimamiwa au Yasiyosimamiwa?
Miundo mikubwa ya lugha kwa kawaida hufunzwa kwa kutumia mbinu inayoitwa ujifunzaji unaosimamiwa. Kwa maneno rahisi, hii ina maana kwamba wanajifunza kutokana na mifano inayowaonyesha majibu sahihi.
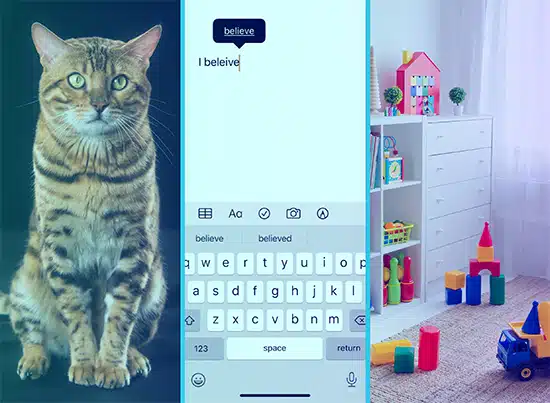 Fikiria unamfundisha mtoto maneno kwa kuwaonyesha picha. Unawaonyesha picha ya paka na kusema "paka," na wanajifunza kuhusisha picha hiyo na neno. Hivyo ndivyo mafunzo yanayosimamiwa yanavyofanya kazi. Mfano huo hupewa maandishi mengi ("picha") na matokeo yanayolingana ("maneno"), na hujifunza kuyalinganisha.
Fikiria unamfundisha mtoto maneno kwa kuwaonyesha picha. Unawaonyesha picha ya paka na kusema "paka," na wanajifunza kuhusisha picha hiyo na neno. Hivyo ndivyo mafunzo yanayosimamiwa yanavyofanya kazi. Mfano huo hupewa maandishi mengi ("picha") na matokeo yanayolingana ("maneno"), na hujifunza kuyalinganisha.
Kwa hivyo, ikiwa unalisha LLM sentensi, inajaribu kutabiri neno linalofuata au kifungu kulingana na kile imejifunza kutoka kwa mifano. Kwa njia hii, hujifunza jinsi ya kutoa maandishi yanayoleta maana na yanayolingana na muktadha.
Hiyo ilisema, wakati mwingine LLM pia hutumia ujifunzaji usiosimamiwa. Hii ni kama kumruhusu mtoto kuchunguza chumba kilichojaa vinyago mbalimbali na kujifunza kuvihusu peke yake. Muundo huangalia data isiyo na lebo, mifumo ya kujifunza, na miundo bila kuambiwa majibu "sahihi".
Masomo yanayosimamiwa hutumia data ambayo imewekewa lebo ya pembejeo na matokeo, tofauti na mafunzo yasiyosimamiwa, ambayo hayatumii data ya matokeo yenye lebo.
Kwa kifupi, LLMs hufunzwa hasa kwa kutumia ujifunzaji unaosimamiwa, lakini pia wanaweza kutumia ujifunzaji usiosimamiwa ili kuboresha uwezo wao, kama vile uchanganuzi wa uchunguzi na kupunguza vipimo.
Je! Kiasi cha Data (Katika GB) Ni Kinachohitajika Ili Kufunza Muundo Kubwa wa Lugha?
Ulimwengu wa uwezekano wa utambuzi wa data ya usemi na utumizi wa sauti ni mkubwa sana, na unatumika katika tasnia kadhaa kwa programu nyingi.
Kufunza muundo mkubwa wa lugha sio mchakato wa saizi moja, haswa linapokuja suala la data inayohitajika. Inategemea rundo la vitu:
- Muundo wa mfano.
- Inahitaji kufanya kazi gani?
- Aina ya data unayotumia.
- Je, ungependa ifanye vizuri kiasi gani?
Hiyo ilisema, mafunzo ya LLM kawaida huhitaji idadi kubwa ya data ya maandishi. Lakini tunazungumza juu ya ukubwa gani? Kweli, fikiria zaidi ya gigabytes (GB). Kwa kawaida tunaangalia terabaiti (TB) au hata petabytes (PB) za data.
Fikiria GPT-3, mojawapo ya LLM kubwa kote. Inafunzwa 570 GB ya data ya maandishi. LLM ndogo huenda zikahitaji kidogo - labda GB 10-20 au hata GB 1 ya gigabaiti - lakini bado ni nyingi.

Lakini sio tu juu ya saizi ya data. Ubora ni muhimu pia. Data inahitaji kuwa safi na tofauti ili kusaidia modeli kujifunza kwa ufanisi. Na huwezi kusahau kuhusu vipande vingine muhimu vya fumbo, kama vile nguvu ya kompyuta unayohitaji, algoriti unazotumia kwa mafunzo, na usanidi wa maunzi ulio nao. Mambo haya yote yana mchango mkubwa katika kutoa mafunzo kwa LLM.
Kuongezeka kwa Miundo Kubwa ya Lugha: Kwa Nini Wao Ni Muhimu
LLM si wazo tu au jaribio tu. Wanazidi kuchukua jukumu muhimu katika mazingira yetu ya kidijitali. Lakini kwa nini hii inatokea? Ni nini hufanya LLM hizi kuwa muhimu sana? Hebu tuchunguze baadhi ya mambo muhimu.
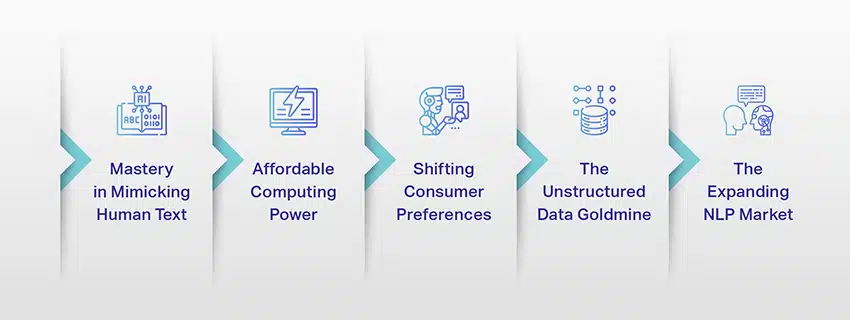
Umahiri katika Kuiga Maandishi ya Binadamu
LLM zimebadilisha jinsi tunavyoshughulikia kazi zinazotegemea lugha. Miundo hii imeundwa kwa kutumia algoriti thabiti za kujifunza kwa mashine, na imeundwa kwa uwezo wa kuelewa nuances ya lugha ya binadamu, ikiwa ni pamoja na muktadha, hisia na hata kejeli, kwa kiasi fulani. Uwezo huu wa kuiga lugha ya binadamu si jambo geni tu, una athari kubwa.
Uwezo wa hali ya juu wa kuunda maandishi wa LLM unaweza kuboresha kila kitu kuanzia uundaji wa maudhui hadi mwingiliano wa huduma kwa wateja.
Fikiria kuwa na uwezo wa kuuliza msaidizi wa kidijitali swali tata na kupata jibu ambalo sio tu lina maana, lakini pia ni thabiti, muhimu, na kutolewa kwa sauti ya mazungumzo. Hiyo ndio LLMs wanawezesha. Zinachochea mwingiliano wa angavu zaidi na unaovutia wa binadamu, unaboresha hali ya utumiaji na ufikiaji wa kidemokrasia kwa habari.
Nguvu ya Affordable Computing
Kupanda kwa LLM haingewezekana bila maendeleo sambamba katika uwanja wa kompyuta. Hasa zaidi, uwekaji demokrasia wa rasilimali za kikokotozi umechukua nafasi kubwa katika mageuzi na kupitishwa kwa LLMs.
Majukwaa yanayotegemea wingu yanatoa ufikiaji usio na kifani kwa rasilimali za utendaji wa juu za kompyuta. Kwa njia hii, hata mashirika madogo na watafiti huru wanaweza kutoa mafunzo kwa miundo ya kisasa ya kujifunza kwa mashine.
Zaidi ya hayo, uboreshaji wa vitengo vya uchakataji (kama vile GPU na TPU), pamoja na kuongezeka kwa kompyuta iliyosambazwa, umefanya iwezekane kutoa mafunzo kwa miundo yenye mabilioni ya vigezo. Ufikiaji huu ulioongezeka wa nguvu za kompyuta unawezesha ukuaji na mafanikio ya LLM, na kusababisha uvumbuzi zaidi na matumizi katika uwanja huo.
Kuhamisha Mapendeleo ya Mtumiaji
Wateja leo hawataki tu majibu; wanataka maingiliano ya kuvutia na yanayohusiana. Kadiri watu wengi wanavyokua wakitumia teknolojia ya kidijitali, ni dhahiri kwamba hitaji la teknolojia inayohisiwa kuwa ya asili zaidi na inayofanana na ya binadamu linaongezeka.LLMs hutoa fursa isiyo na kifani ili kukidhi matarajio haya. Kwa kutoa maandishi yanayofanana na binadamu, miundo hii inaweza kuunda hali ya utumiaji ya kidijitali inayovutia, ambayo inaweza kuongeza kuridhika na uaminifu wa mtumiaji. Iwe ni gumzo za AI zinazotoa huduma kwa wateja au visaidizi vya sauti vinavyotoa masasisho ya habari, LLM zinaanzisha enzi ya AI ambayo inatuelewa zaidi.
Data Isiyo na muundo Goldmine
Data isiyo na muundo, kama vile barua pepe, machapisho ya mitandao ya kijamii na hakiki za wateja, ni hazina ya maarifa. Inakadiriwa kuwa imekwisha 80% ya data ya biashara haina muundo na inakua kwa kiwango cha 55% kwa mwaka. Data hii ni mgodi wa dhahabu kwa biashara ikiwa itatumiwa ipasavyo.
LLM zinatumika hapa, zikiwa na uwezo wao wa kuchakata na kuleta maana ya data kama hiyo kwa kiwango. Wanaweza kushughulikia kazi kama vile uchanganuzi wa hisia, uainishaji wa maandishi, kutoa maelezo, na zaidi, kwa hivyo kutoa maarifa muhimu.
Iwe ni kutambua mitindo kutoka kwa machapisho ya mitandao ya kijamii au kupima maoni ya wateja kutokana na maoni, LLMs zinasaidia biashara kuvinjari kiasi kikubwa cha data ambayo haijaundwa na kufanya maamuzi yanayotokana na data.
Kupanua Soko la NLP
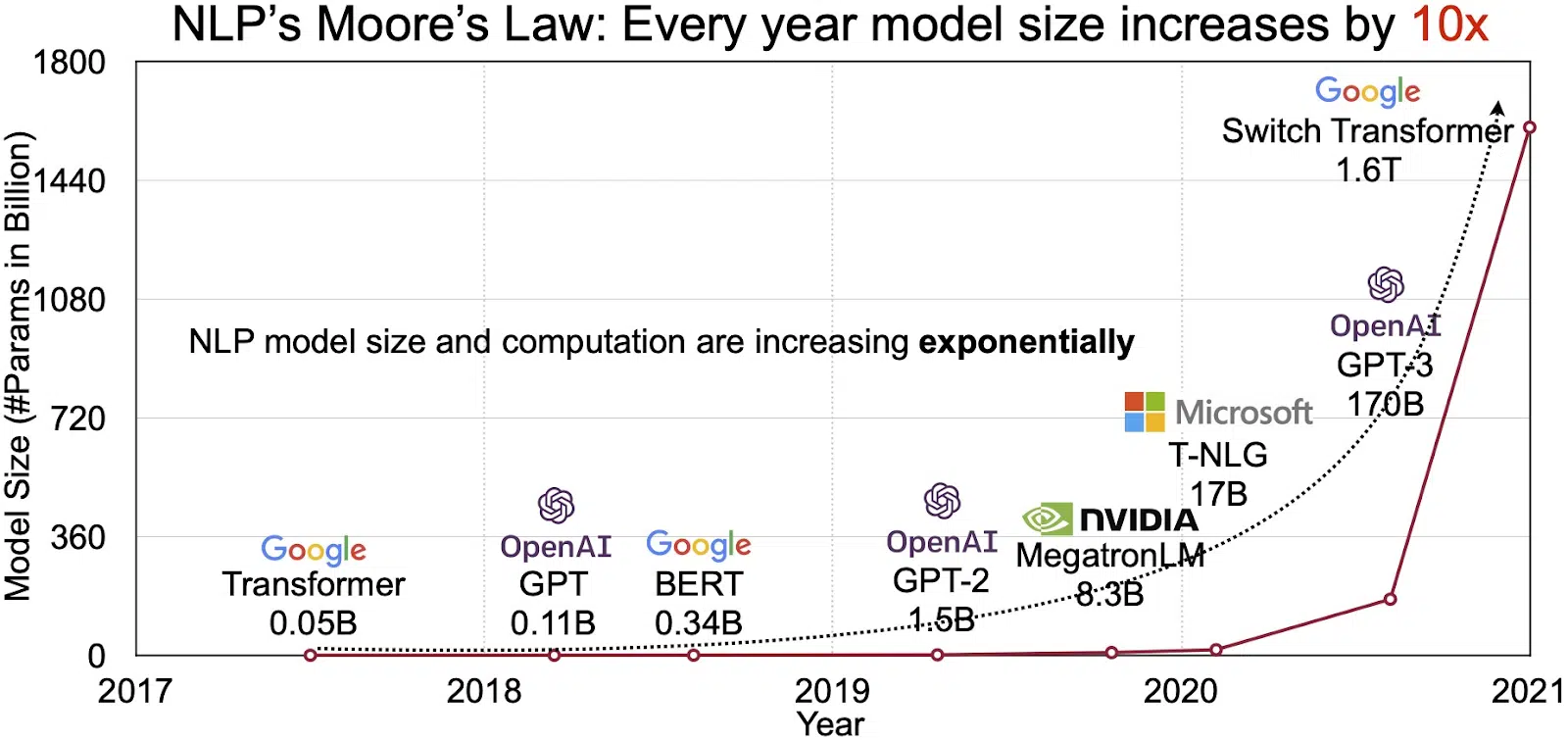
Uwezo wa LLM unaonyeshwa katika soko linalokua kwa kasi la usindikaji wa lugha asilia (NLP). Wachambuzi wanapanga soko la NLP kupanua kutoka $11 bilioni mwaka 2020 hadi zaidi ya $35 bilioni ifikapo 2026. Lakini sio tu saizi ya soko inayokua. Mifano yenyewe inakua pia, kwa ukubwa wa kimwili na kwa idadi ya vigezo vinavyoshughulikia. Mabadiliko ya LLM kwa miaka mingi, kama inavyoonekana kwenye takwimu hapa chini (chanzo cha picha: kiungo), inasisitiza ugumu na uwezo wao unaoongezeka.
Kesi Maarufu za Matumizi ya Miundo Kubwa ya Lugha
Hapa kuna baadhi ya kesi za juu na zinazoenea za matumizi ya LLM:
- Kuzalisha Maandishi ya Lugha Asilia: Miundo Kubwa ya Lugha (LLMs) inachanganya uwezo wa akili bandia na isimu kokotoa ili kutoa matini kwa uhuru katika lugha asilia. Wanaweza kukidhi mahitaji mbalimbali ya mtumiaji kama vile kuandika makala, kuunda nyimbo, au kushiriki katika mazungumzo na watumiaji.
- Tafsiri kupitia Mashine: LLM zinaweza kutumika kwa ufanisi kutafsiri maandishi kati ya jozi yoyote ya lugha. Miundo hii hutumia algoriti za ujifunzaji wa kina kama vile mitandao ya neural inayojirudia ili kuelewa muundo wa lugha wa lugha chanzo na lengwa, na hivyo kuwezesha utafsiri wa matini chanzi hadi lugha inayotakikana.
- Kutengeneza Maudhui Asili: LLMs zimefungua njia za mashine kutoa maudhui yenye mshikamano na mantiki. Maudhui haya yanaweza kutumika kuunda machapisho ya blogu, makala na aina nyingine za maudhui. Miundo huingia katika uzoefu wao wa kina wa kujifunza ili kufomati na kupanga maudhui kwa njia ya riwaya na ya kirafiki.
- Uchambuzi wa hisia: Utumizi mmoja wa kuvutia wa Miundo Kubwa ya Lugha ni uchanganuzi wa hisia. Katika hili, modeli hufunzwa kutambua na kuainisha hali za kihisia na hisia zilizopo katika maandishi ya maelezo. Programu inaweza kutambua hisia kama vile uchanya, uzembe, kutoegemea upande wowote, na maoni mengine tata. Hii inaweza kutoa maarifa muhimu katika maoni ya wateja na maoni kuhusu bidhaa na huduma mbalimbali.
- Kuelewa, Kufupisha, na Kuainisha Maandishi: LLM huanzisha muundo unaofaa kwa programu ya AI kutafsiri maandishi na muktadha wake. Kwa kuagiza kielelezo kuelewa na kuchunguza idadi kubwa ya data, LLM huwezesha miundo ya AI kuelewa, kufupisha, na hata kuainisha maandishi katika miundo na ruwaza mbalimbali.
- Kujibu Maswali: Miundo Kubwa ya Lugha huandaa mifumo ya Kujibu Maswali (QA) yenye uwezo wa kutambua kwa usahihi na kujibu swali la lugha asilia la mtumiaji. Mifano maarufu ya kesi hii ya utumiaji ni pamoja na ChatGPT na BERT, ambayo huchunguza muktadha wa swali na kuchuja mkusanyiko mkubwa wa maandishi ili kutoa majibu yanayofaa kwa maswali ya watumiaji.

Uwekaji Tagi wa Sehemu ya Hotuba (POS).
Maneno katika sentensi huwekwa alama za uamilifu wake wa kisarufi, kama vile vitenzi, nomino, vivumishi, n.k. Utaratibu huu unamsaidia modeli katika kuelewa sarufi na uhusiano kati ya maneno.

Utambuzi wa Vyombo Vilivyoitwa (NER)
Huluki zilizotajwa kama vile mashirika, maeneo na watu walio ndani ya sentensi zimetiwa alama. Zoezi hili husaidia modeli katika kufasiri maana za kisemantiki za maneno na vishazi na hutoa majibu sahihi zaidi.

Uchanganuzi wa sentensi
Data ya maandishi hupewa lebo za hisia kama vile chanya, zisizoegemea upande wowote au hasi, zinazosaidia kielelezo kufahamu sauti ya chini ya kihisia ya sentensi. Ni muhimu sana katika kujibu maswali yanayohusu mihemko na maoni.
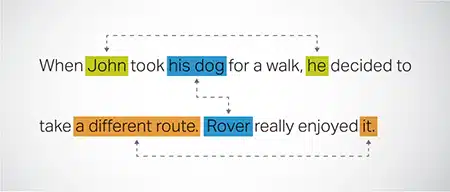
Azimio la Marejeleo
Kubainisha na kutatua matukio ambapo huluki sawa inarejelewa katika sehemu tofauti za maandishi. Hatua hii humsaidia mwanamitindo kuelewa muktadha wa sentensi, hivyo kusababisha majibu madhubuti.
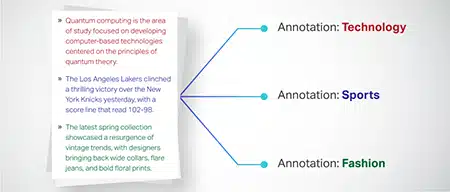
Uainishaji wa Nakala
Data ya maandishi imeainishwa katika vikundi vilivyobainishwa awali kama vile ukaguzi wa bidhaa au makala ya habari. Hii husaidia mtindo katika kutambua aina au mada ya maandishi, na kutoa majibu muhimu zaidi.
Sadaka ya Shaip
Shaip inatoa huduma mbalimbali ili kusaidia mashirika kudhibiti, kuchanganua na kufaidika zaidi na data zao.
Uchakataji wa Mtandao wa Data
Huduma moja muhimu inayotolewa na Shaip ni kukwangua data. Hii inahusisha uchimbaji wa data kutoka kwa URL mahususi za kikoa. Kwa kutumia zana na mbinu za kiotomatiki, Shaip anaweza kufuta data nyingi kwa haraka na kwa ufanisi kutoka kwa tovuti mbalimbali, Mwongozo wa Bidhaa, Hati za Kiufundi, Mijadala ya Mtandaoni, Maoni ya Mtandaoni, Data ya Huduma kwa Wateja, Hati za Kudhibiti Sekta n.k. Mchakato huu unaweza kuwa wa thamani sana kwa biashara. kukusanya data muhimu na mahususi kutoka kwa wingi wa vyanzo.

Tafsiri ya Mashine
Tengeneza miundo kwa kutumia seti pana za data za lugha nyingi zilizooanishwa na manukuu yanayolingana ili kutafsiri maandishi katika lugha mbalimbali. Utaratibu huu husaidia kuondoa vikwazo vya lugha na kukuza upatikanaji wa taarifa.
Uchimbaji na Uundaji wa Jamii
Shaip inaweza kusaidia katika uchimbaji na uundaji wa taksonomia. Hii inahusisha kuainisha na kuainisha data katika muundo uliopangwa unaoakisi uhusiano kati ya pointi tofauti za data. Hii inaweza kuwa muhimu hasa kwa biashara katika kupanga data zao, na kuifanya ipatikane zaidi na iwe rahisi kuchanganua. Kwa mfano, katika biashara ya e-commerce, data ya bidhaa inaweza kuainishwa kulingana na aina ya bidhaa, chapa, bei, n.k., ili kurahisisha wateja kuvinjari katalogi ya bidhaa.
Ukusanyaji wa Takwimu
Huduma zetu za ukusanyaji wa data hutoa data muhimu ya ulimwengu halisi au ya sintetiki inayohitajika kwa mafunzo ya algoriti za AI na kuboresha usahihi na ufanisi wa miundo yako. Data haina upendeleo, kimaadili na inatolewa kwa kuwajibika huku tukizingatia ufaragha na usalama wa data.

Swali na Majibu
Kujibu maswali (QA) ni sehemu ndogo ya usindikaji wa lugha asilia inayolenga kujibu maswali kiotomatiki katika lugha ya binadamu. Mifumo ya QA imefunzwa juu ya maandishi na msimbo wa kina, na kuiwezesha kushughulikia aina mbalimbali za maswali, ikiwa ni pamoja na yale ya kweli, ya ufafanuzi na yanayotegemea maoni. Maarifa ya kikoa ni muhimu kwa kutengeneza miundo ya QA iliyoundwa kwa nyanja mahususi kama vile usaidizi wa wateja, huduma ya afya, au ugavi. Hata hivyo, mbinu za uzalishaji za QA huruhusu miundo kutoa maandishi bila ujuzi wa kikoa, kutegemea muktadha pekee.
Timu yetu ya wataalamu inaweza kusoma kwa uangalifu hati au miongozo ya kina ili kutengeneza jozi za Majibu ya Maswali, kuwezesha uundaji wa AI ya Kuzalisha kwa biashara. Mbinu hii inaweza kushughulikia maswali ya watumiaji kwa ufanisi kwa kuchimba habari muhimu kutoka kwa shirika kubwa. Wataalamu wetu walioidhinishwa huhakikisha utengenezaji wa jozi za ubora wa juu za Maswali na Majibu ambazo hupitia mada na vikoa mbalimbali.

Muhtasari wa Maandishi
Wataalamu wetu wana uwezo wa kutokeza mazungumzo ya kina au mazungumzo marefu, kutoa muhtasari mfupi na wa maarifa kutoka kwa data pana ya maandishi.

Kizazi cha maandishi
Funza miundo kwa kutumia mkusanyiko mpana wa maandishi katika mitindo mbalimbali, kama vile makala za habari, hadithi za kubuni na ushairi. Miundo hii inaweza kisha kutoa aina mbalimbali za maudhui, ikiwa ni pamoja na vipande vya habari, maingizo kwenye blogu, au machapisho ya mitandao ya kijamii, kutoa suluhisho la gharama nafuu na la kuokoa muda kwa ajili ya kuunda maudhui.
Utambuzi wa Hotuba
Kuza miundo yenye uwezo wa kuelewa lugha inayozungumzwa kwa matumizi mbalimbali. Hii ni pamoja na wasaidizi walioamilishwa kwa kutamka, programu ya imla na zana za kutafsiri katika wakati halisi. Mchakato huo unahusisha kutumia mkusanyiko wa data wa kina unaojumuisha rekodi za sauti za lugha inayozungumzwa, zilizooanishwa na nakala zao zinazolingana.

Mapendekezo ya Bidhaa
Tengeneza miundo kwa kutumia hifadhidata nyingi za historia ya ununuzi wa wateja, ikijumuisha lebo zinazoonyesha bidhaa ambazo wateja wanapendelea kununua. Lengo ni kutoa mapendekezo sahihi kwa wateja, na hivyo kuongeza mauzo na kuongeza kuridhika kwa wateja.
Maelezo ya Picha
Badilisha mchakato wako wa kutafsiri picha kwa kutumia huduma yetu ya hali ya juu, inayoendeshwa na AI. Tunapenyeza uchangamfu katika picha kwa kutoa maelezo sahihi na yenye maana kimuktadha. Hii hufungua njia ya ushiriki wa kibunifu na uwezekano wa mwingiliano na maudhui yako ya kuona kwa hadhira yako.

Mafunzo ya Huduma za Maandishi-hadi-Hotuba
Tunatoa seti pana ya data inayojumuisha rekodi za sauti za matamshi ya binadamu, bora kwa mafunzo ya miundo ya AI. Miundo hii inaweza kutoa sauti za asili na za kuvutia za programu zako, hivyo basi kutoa hali ya kipekee na ya kina kwa watumiaji wako.



